01 · Introduction
In many traditional database environments, high availability comes with a trade-off. You add redundant servers, duplicate storage, and complex failover mechanisms — but every additional layer introduces more management overhead and sometimes even reduces performance during normal operations.
Oracle Exadata takes a different approach. Instead of treating high availability as an afterthought, it builds resilience into every layer of the architecture — from Compute Nodes and Storage Cells to ASM, Oracle RAC, intelligent networking, and automatic redundancy.
The result isn't just a system that survives failures. It's a platform that continues delivering high performance even while components fail, are patched, or are replaced.
Q: How does Oracle Exadata deliver high availability without sacrificing performance?
A: Exadata co-engineers hardware and software so that ASM mirroring, RAC active-active clustering, Smart Scan offloading, and Write-Back Flash Cache coordination work as one unified system — keeping databases online and fast even during disk failures, node crashes, and rolling maintenance.
02 · Why Isn't Redundancy Alone Enough?
For decades, the standard recipe for enterprise availability has been simple: if one component is good, two must be better. IT departments bought pairs of fibre channel switches, duplicate disk arrays, and multi-node compute clusters. Yet systems still crashed, applications still stalled, and databases still suffered catastrophic performance degradation during partial outages.
Traditional Redundancy Approaches vs. Application Reality
Traditional setups rely heavily on Active-Passive architectures. Look at this model closely: you have a secondary server sitting completely idle, consuming power, cooling, and licensing capital while waiting for the primary node to die. When a failure occurs, a complex clusterware script attempts to unmount storage from the dead host, remount it on the passive host, start the database instance, and run crash recovery.
During this window — which can easily stretch from several minutes to over an hour — the application is entirely offline.
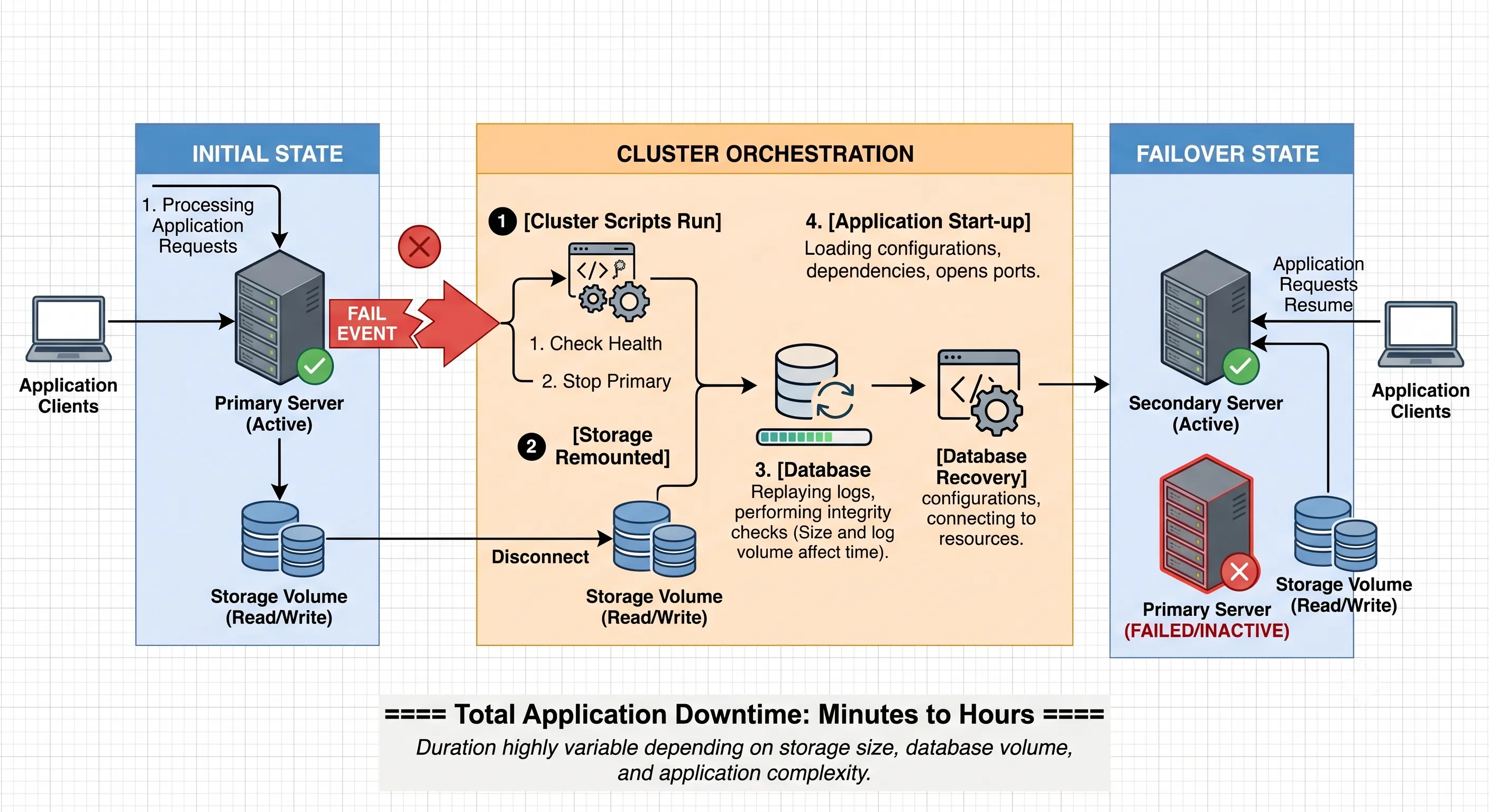
Figure 1 · Active-Passive failover windows vs. Exadata's always-on architecture
Even in Active-Active configurations built on generic hardware, challenges remain acute. True availability is not merely about keeping a login prompt accessible; it is about sustaining production-grade throughput. When duplicate hardware is stitched together using generic protocols, several vulnerabilities emerge:
Split-Brain Scenarios
If the heartbeat network between nodes drops, both servers may believe the other is dead. Without tightly integrated fencing mechanisms, both nodes may attempt to write to the same storage blocks simultaneously, corrupting the database beyond immediate repair.
The Rebuild Bottleneck
When a traditional storage array loses a disk, it initiates a RAID rebuild that can consume up to 80% of the storage controller's IOPS — causing database performance to crater exactly when the business needs it most.
Hidden Single Points of Failure
Redundant power supplies connected to the same PDU, or dual-port HBAs sharing a single internal PCIe bus, create an illusion of safety while leaving the system vulnerable to isolated physical failures.
Simply adding duplicate hardware does not guarantee availability. Without deep, cross-layer software awareness, hardware redundancy merely moves the point of failure from the physical asset to the orchestration layer.
03 · How Does Oracle ASM Protect Your Data?
Q: How does Oracle ASM protect Exadata data?
A: ASM replaces rigid hardware RAID with file-level software mirroring across failure groups — typically one per Storage Cell — so a lost disk or entire cell triggers automatic online drop and intelligent rebalance without taking the database offline.
At the core of Exadata's storage resilience is Oracle Automatic Storage Management (ASM). Rather than relying on rigid hardware RAID controllers that abstract disks into inflexible logical unit numbers (LUNs), Exadata uses ASM to turn raw physical storage into dynamic, intelligent pools of data.
The ASM Architecture Layer Cake
To understand how ASM safeguards data without introducing bottlenecks, we must look at how it maps physical media to logical database structures:
- Disk Groups — The highest level of abstraction. A disk group aggregates storage capacity and distributes database files evenly across all underlying disks.
- Failure Groups — A collection of disks that share a common physical dependency. In an Exadata environment, each individual Storage Cell is configured as its own Failure Group, ensuring that if an entire storage server loses power, its mirrored data resides safely on completely separate physical servers.
- Grid Disks — Physical HDDs or NVMe flash drives within a Storage Cell are partitioned into Grid Disks — the building blocks presented directly to ASM.
Automatic Data Mirroring and Failure Tolerances
ASM avoids hardware RAID striping in favor of file-level software mirroring. When a database block is written, ASM writes a primary copy (the primary extent) to one Failure Group and a secondary copy (the mirror extent) to a different Failure Group. Exadata configurations typically leverage two modes of ASM redundancy:
| Redundancy Mode | Mirroring | Minimum Cells | Failure Tolerance |
|---|---|---|---|
| Normal Redundancy | Two-way mirroring | 3 Storage Cells | Survives loss of 1 cell or disk |
| High Redundancy | Three-way mirroring | 5 Storage Cells | Survives simultaneous loss of 2 cells or disks |
Real-World DBA Scenario: The Self-Healing Storage Rebalance
Imagine a production Exadata X10M quarter-rack environment where Grid Disk DATA_CD_04_cell02 experiences a sudden hardware failure. In a traditional SAN, this triggers a stressful night for the DBA and storage team. On Exadata, the system handles it automatically.
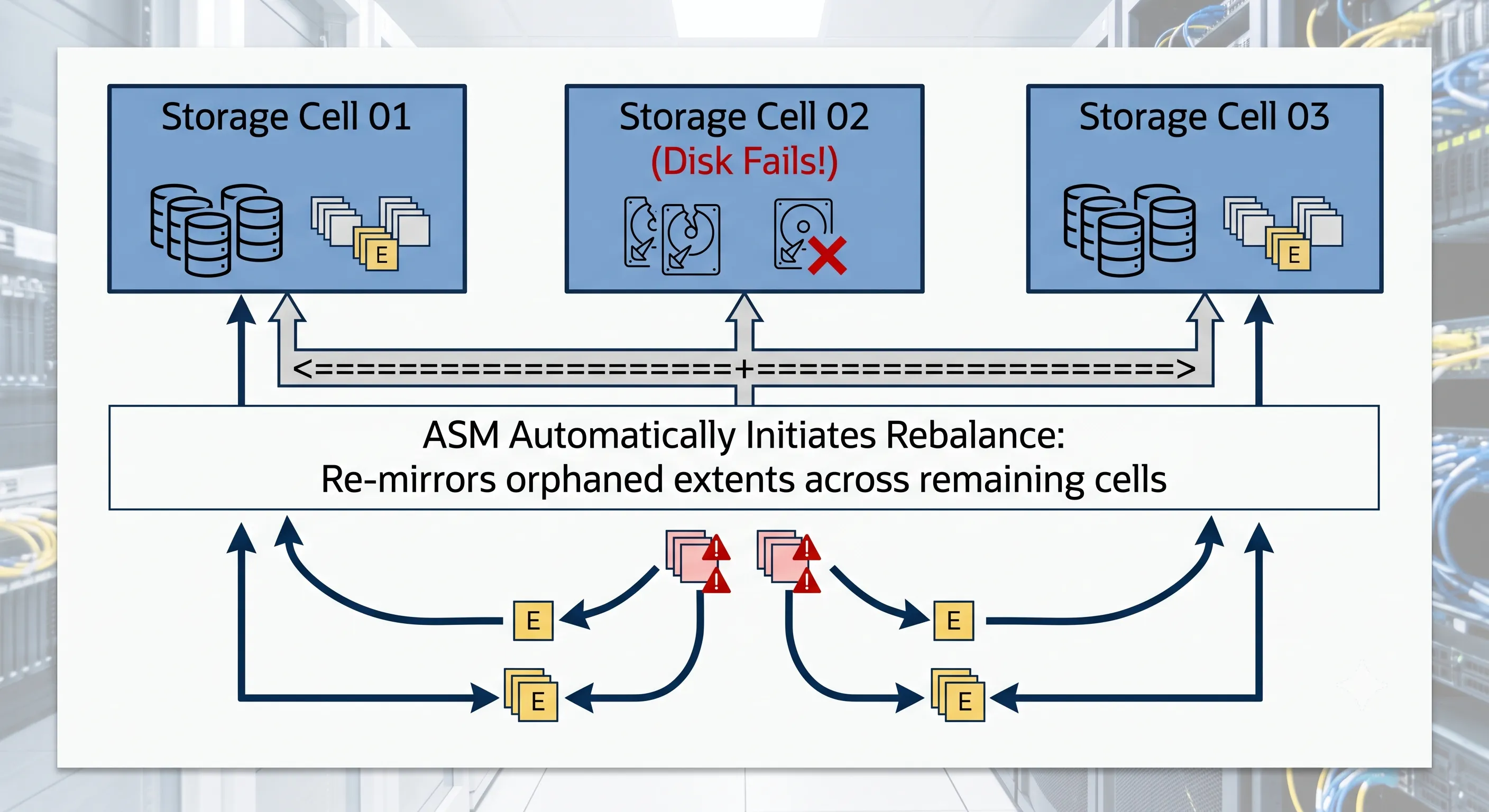
Figure 2 · ASM self-healing rebalance — from detection to full redundancy restoration
- DetectionThe Exadata Storage Server software detects media errors and alerts the ASM instance on the compute nodes via the internal RoCE network.
- Dropping the DiskASM issues an internal
ALTER DISKGROUP ... DROP DISKcommand with the ONLINE clause. The disk is marked offline, and the database continues running without interruption, reading mirrored extents from surviving cells. - Intelligent RebalancingASM reads the partner extents of the data that was on the failed disk and writes new mirror copies across all remaining healthy disks in the disk group.
Unlike traditional RAID rebuilds that sequentially scan an entire drive, ASM balances only the actual data stored on the failed disk. If a 14TB disk only contains 2TB of data, only 2TB is moved. Because this work is distributed across every remaining drive in the cluster, the rebalance completes in minutes rather than hours, minimizing performance degradation.
04 · How Does Oracle RAC Eliminate Downtime?
Q: How does Oracle RAC eliminate downtime on Exadata?
A: RAC runs multiple active database instances across compute nodes simultaneously. When a node fails, FAN, Transaction Guard, and Application Continuity redirect sessions to surviving nodes in seconds — without waiting for TCP timeouts or manual failover scripts.
While ASM protects the storage layer, Oracle Real Application Clusters (RAC) ensures compute availability. In an Exadata environment, multiple database instances run simultaneously across distinct compute nodes, accessing the same underlying data assets concurrently.
Active-Active Multi-Node Processing
Oracle RAC is a true active-active clustering engine. There are no passive nodes idling in standby mode. Applications can connect to any compute node to execute queries, run reports, or process transactions. The coordination between these nodes is managed by Oracle Grid Infrastructure, which utilizes high-speed RoCE interconnects to pass database blocks directly between the memory caches of different servers via Cache Fusion.
Bulletproof Session Failover and Load Balancing
When a compute node takes a hit — whether from a hardware fault or an OS panic — Exadata prevents application downtime through an integrated client failover stack:
Fast Application Notification (FAN)
The moment a compute node fails, clusterware broadcasts a FAN event to the application tier. Instead of waiting for a standard TCP timeout (which can take several minutes), application connection pools immediately sever connections to the dead node.
Transaction Guard
Ensures transaction idempotency. When a connection drops mid-transaction, Transaction Guard provides a reliable tool to determine if the last SQL statement committed before the crash, preventing duplicate payments or orders.
Application Continuity (AC)
For applications utilizing supported Oracle drivers, AC captures the session state and database interactions. If a node fails, AC recreates the session on a surviving node, replays the uncommitted transaction in flight, and returns control to the user.
Production Failure Timeline
To understand why users rarely notice a node failure, consider this timeline of a hardware crash on Compute Node 1:
| Time | Event | User Impact |
|---|---|---|
| T+0 ms | Compute Node 1 stops responding; Grid Infrastructure detects missed heartbeat | None — sessions on other nodes continue normally |
| T+1–3 s | FAN event broadcast; connection pools on Node 1 severed instantly | Brief pause for affected sessions only |
| T+3–10 s | Surviving nodes absorb orphaned sessions; Cache Fusion serves required blocks | Application Continuity replays in-flight transactions |
| T+10–30 s | Cluster rebalances workload; evicted node fenced from shared storage | Users on surviving nodes see no interruption |
| T+minutes | DBA receives alert; failed node diagnosed and scheduled for replacement | Production traffic fully restored on remaining nodes |
05 · What Happens If a Storage Cell Suddenly Fails?
Q: What happens when an entire Exadata Storage Cell fails?
A: Compute nodes detect the loss within milliseconds, ASM redirects I/O to mirror extents on surviving cells, Smart Scan work is redistributed mid-query, and after the DISK_REPAIR_TIME window ASM rebalances data to restore full redundancy — all without crashing the database.
While individual disk failures are common, the sudden death of an entire storage server (due to an internal component failure or a severed power cord) represents a far more severe architectural threat. Oracle engineered Exadata's hardware and software to natively handle this scenario without causing database crashes.
Step-by-Step Anatomy of a Storage Cell Outage
Let's walk through exactly what happens under the hood when a storage cell drops offline out of nowhere during a heavy batch processing cycle.
- Step 1: Immediate Fault DetectionThe Exadata Storage Server software running on the cell stops communicating. Compute nodes monitor these connections continuously using low-latency network heartbeats over the RoCE fabric. Within milliseconds of a missed heartbeat, the compute nodes flag the cell as unreachable.
- Step 2: Instantaneous I/O ReroutingWhen a database process attempts to read a block from the failed storage cell and encounters a timeout, the ASM disk driver intercept layer immediately redirects the read request to the partner mirror extent located on a surviving storage cell. The application remains unaware that a failure occurred.
- Step 3: Mid-Query Smart Scan ContinuationIf the database is executing a massive parallel Smart Scan, the failure of a cell mid-query does not abort the operation. The database compute instance automatically recalculates the granules of work assigned to the failed cell and redistributes those scan tasks to the remaining storage servers.
- Step 4: Safe Rebalancing After TimeoutASM does not immediately assume a dropped cell is dead forever — it could be undergoing a brief reboot. It waits for a user-configurable period (defined by the
DISK_REPAIR_TIMEattribute, typically set to several hours). If the cell does not return within this window, ASM initiates an automated data rebalance.
06 · How Does Oracle Exadata Maintain Performance During Failures?
Keeping a database online during a hardware failure is only half the battle. If performance degrades so heavily that timeouts trigger across your application server pool, the system is functionally offline to your customers. Exadata uses integrated resource allocation mechanisms to maintain predictable performance even when running on reduced hardware.
Smart Resource Management and Cell Offloading
In standard SAN-based architectures, when an array controller fails, the remaining controllers must take over its workload, often leading to cache saturation and bus contention. Exadata avoids this through its highly distributed architecture. Because query processing is offloaded directly to the CPUs inside the individual Storage Cells via Smart Scan, the compute layer is insulated from raw I/O bottlenecks.
When a storage cell fails, the loss of processing power is linear and predictable. For instance, in an Exadata deployment with 12 storage cells, losing one cell reduces aggregate storage processing capacity by only 8.3%. The surviving 11 cells continue performing Smart Scans independently, ensuring that system throughput remains high.
Flash Cache Resiliency and Write-Back Protection
Exadata's Smart Flash Cache sits in front of mechanical spinning disks to accelerate reads and writes. It features a sophisticated, high-availability architecture:
- Exadata Smart Flash Log — To guarantee that crucial database log writes are never delayed by a degraded flash module or disk drive, log writes are issued simultaneously to both the physical disks and the ultra-low-latency NVMe flash memory. Whichever medium responds first satisfies the request, keeping write latencies consistent.
- Write-Back Flash Cache Coordination — When Exadata is configured in Write-Back Flash Cache mode, data dirty blocks are mirrored across the flash caches of different storage cells. If a cell dies, no unwritten database blocks are lost because the surviving cell contains the dirty mirror block.
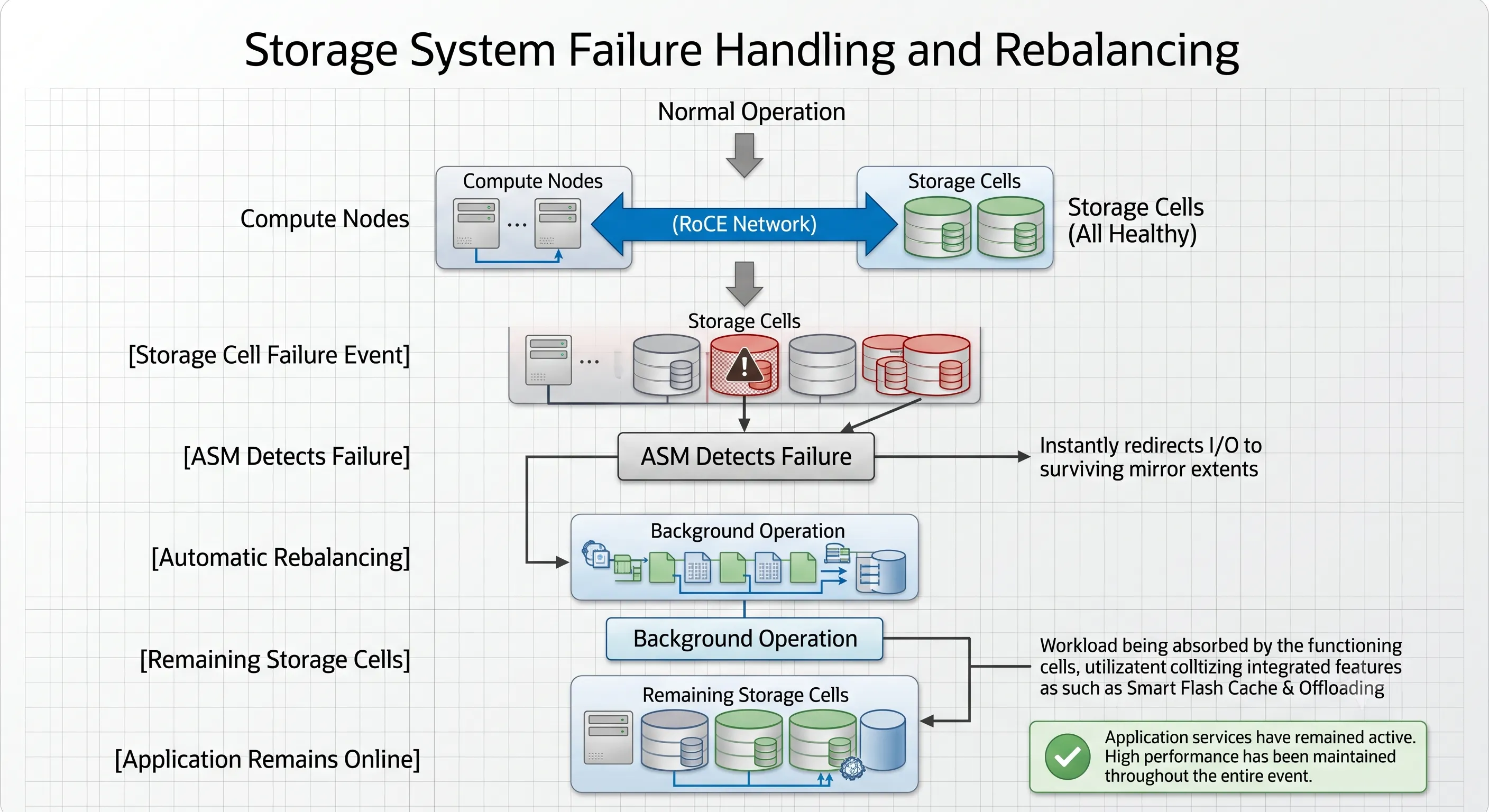
Figure 3 · Oracle Exadata Automatic Failover Workflow — ASM, RAC, and Flash Cache coordination
07 · How Do Rolling Patching and Maintenance Happen Without Downtime?
Q: Can Exadata be patched without downtime?
A: Yes. Exadata supports rolling maintenance — compute nodes and storage cells are patched one at a time while the rest of the grid continues serving production traffic, with automated pre-flight checks via patchmgr enforcing redundancy safety guardrails.
If we look at actual production logs, unexpected hardware failures rarely cause the most downtime — planned maintenance windows do. Operating system patches, firmware updates, database upgrades, and security fixes often require extensive maintenance windows that disrupt business operations. Exadata eliminates these service disruptions by natively supporting rolling maintenance workflows.
The Mechanics of Rolling Upgrades
Because every component within the Exadata ecosystem is deployed in a redundant grid cluster, software and firmware updates can be applied to one node at a time while the rest of the infrastructure continues to handle production traffic.
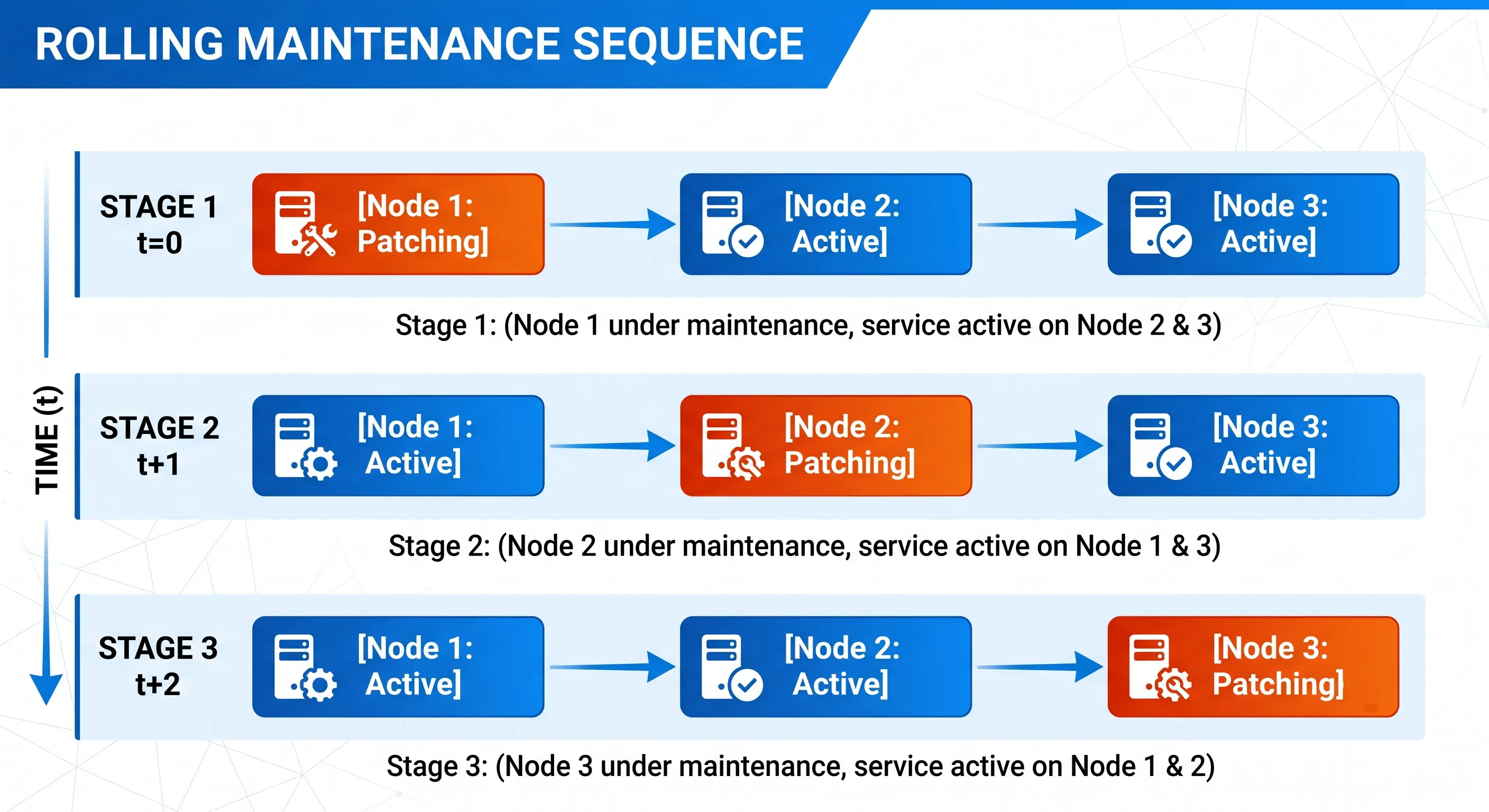
Figure 4 · Rolling upgrades — one node at a time, zero application downtime
Compute Node Patching
Using Oracle Grid Infrastructure, a DBA can place a single compute node into maintenance mode. Active user sessions are drained gracefully to other nodes using FAN and Application Continuity. The server is then patched, updated, rebooted, and reintroduced to the cluster before the next node is processed.
Storage Cell Patching
Storage cells are updated using a similar approach via the cellcli utility. Before the software takes the cell offline, it verifies that ASM has confirmed all disk groups are in a healthy, fully mirrored state. The cell is then updated, rebooted, and its flash cache re-warmed before the system moves on to the next storage target.
Operational Guardrails and Best Practices
- Pre-flight Checks: The Exadata patching utility (
patchmgr) executes hundreds of automated pre-checks to verify cluster health, network routing, and ASM disk status before modifying any code. - High-Redundancy Safety: If a system is configured with Normal Redundancy, you cannot take a second storage cell offline if one is already undergoing maintenance. The software prevents human errors from accidentally causing data unavailability.
08 · How Does Oracle Exadata Prepare for Complete Site Failures?
While RAC and ASM protect a single Exadata rack from internal component failures, they cannot safeguard operations against localized physical disasters, such as a major data center power outage, flooding, or regional network fiber cuts. For true business continuity, local cluster high availability must be coupled with a robust disaster recovery framework.
Oracle Data Guard and Active Data Guard Integration
Exadata pairs with Oracle Data Guard and Active Data Guard to extend availability across geographic distances. In this configuration, a primary Exadata system continually transmits database transaction logs (Redo Logs) over a secure wide-area network (WAN) to a secondary standby Exadata system located at a remote disaster recovery site.
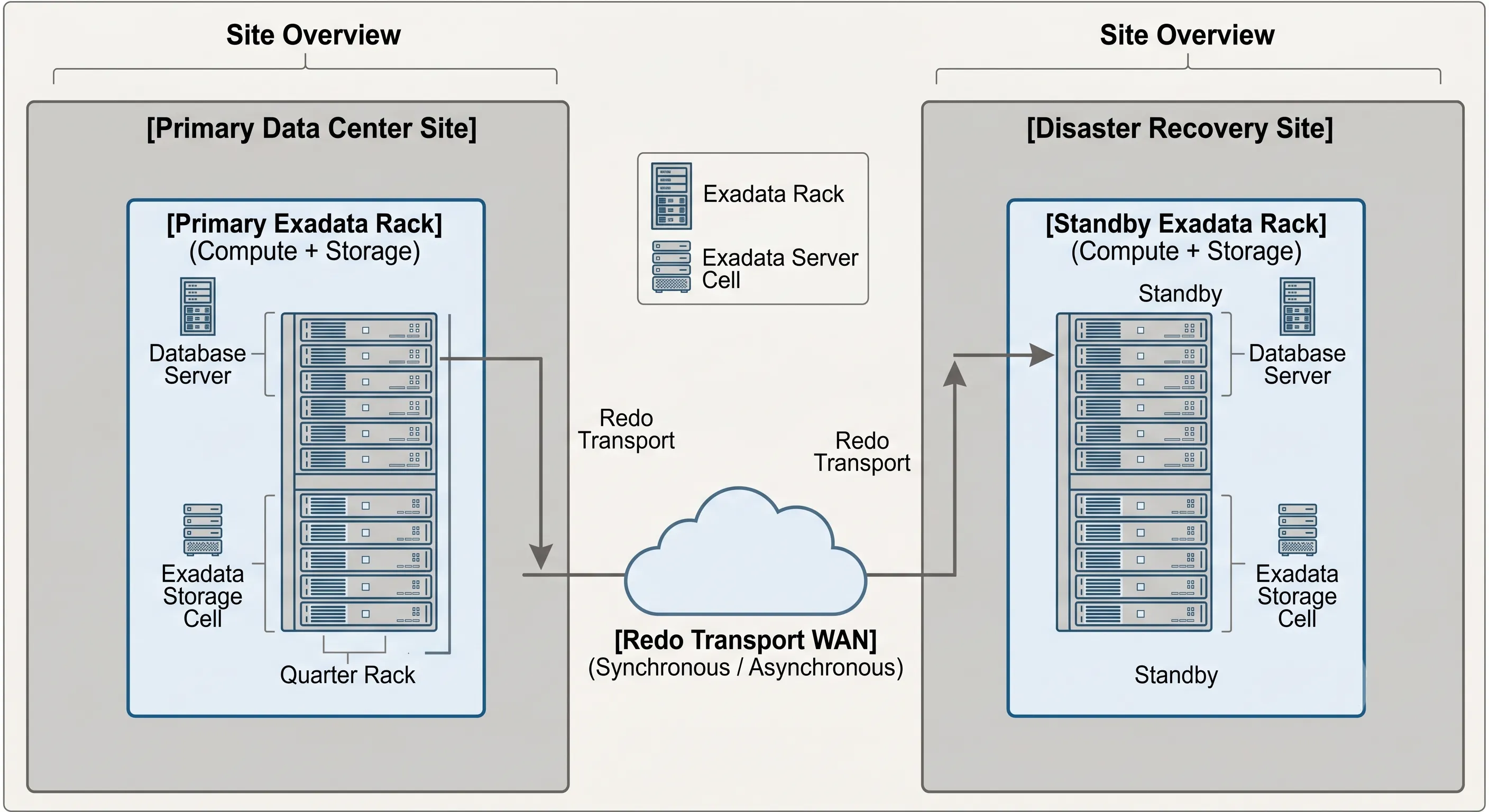
Figure 5 · Data Guard extends Exadata HA beyond the rack to geographic disaster recovery
When Data Guard Complements RAC
It is important to understand the division of responsibilities between these two technologies:
| Technology | Protects Against | Scope |
|---|---|---|
| Oracle RAC | Compute node failure, local hardware faults, OS panics | Single rack / data center — immediate failover inside the same room |
| Oracle Data Guard | Total data center outage, site-level disasters, data corruption | Geographic — remote standby with configurable RPO (RPO = 0 in Maximum Protection Mode) |
Furthermore, Active Data Guard allows the standby Exadata system to remain read-only while replication is active. This means your disaster recovery footprint isn't sitting idle; it can be used to offload heavy reporting applications, read-only analytics, and fast backups from the primary production cluster.
09 · Common Misconceptions About High Availability
Even experienced infrastructure professionals can fall prey to architectural myths regarding high availability. Let's clarify a few common misconceptions within the context of Oracle Exadata.
Misconception 1: "Oracle RAC is a complete backup solution."
The Reality: RAC is a real-time compute availability solution. If an unvalidated application script accidentally executes a DROP TABLE command, RAC will execute that command simultaneously across all nodes within milliseconds. You still need a robust backup strategy (such as RMAN) and flashback technologies to recover from logical data corruption or human error.
Misconception 2: "ASM completely replaces the need for traditional backups."
The Reality: ASM mirrors data extents across multiple physical storage servers to prevent downtime from hardware faults. It does not provide historical point-in-time recovery. If your database suffers a logical corruption or ransomware attack, an ASM mirror simply copies the corrupted blocks. Backups to independent media remain a core requirement.
Misconception 3: "Adding more nodes always guarantees higher availability."
The Reality: Adding nodes beyond your capacity needs can introduce unnecessary architectural complexity. Each additional node increases cluster heartbeat overhead, inter-node block pinging via Cache Fusion, and the general surface area for OS and configuration drift. The goal should be optimal sizing with N+1 redundancy, rather than uncontrolled horizontal expansion.
Misconception 4: "Storage redundancy alone prevents application downtime."
The Reality: Storage redundancy keeps the disk blocks accessible, but it does nothing to protect against server crashes, operating system panics, or network drops. True high availability requires a coordinated stack where the application driver, network switches, cluster software, and storage layer act as a single, unified system.
10 · Production Best Practices for Exadata High Availability
To achieve the maximum possible uptime on an Exadata platform, adhere to these battle-tested engineering best practices:
- Enforce Strict High Redundancy for Mission-Critical DataFor core financial or health systems, configure ASM disk groups with High Redundancy (3-way mirroring). This ensures that even during a rolling patch window (when one cell is offline), the system can still tolerate an unexpected hardware failure on a separate disk or cell without data loss.
- Deploy Validated Client Connection StringsEnsure that your application connection strings use the recommended Oracle parameters, including
RETRY_COUNT,RETRY_DELAY, andCONNECT_TIMEOUT. This allows the application to seamlessly bypass a failed compute node during a failover event. - Configure and Monitor ExaWatcher and AWRRegularly review Automatic Workload Repository (AWR) reports and analyze ExaWatcher diagnostic data. Pay close attention to inter-cluster interconnect latencies and cell-side I/O response times to identify bottlenecks before they cause node evictions.
- Execute Regular, Scheduled Failover DrillsHigh availability is only as good as its last successful test. Schedule non-disruptive rolling maintenance windows and perform planned Data Guard switchovers at least once a year to ensure that your operational teams know exactly how the system behaves under pressure.
- Maintain Symmetric Compute Capacity PlanningEnsure that if one compute node fails, the remaining nodes have sufficient CPU and memory headroom to absorb the orphaned workload. Running compute nodes at greater than 80% utilization during normal operations leaves little room for node-level failover.
11 · Technical Comparison: Traditional Architecture vs. Oracle Exadata
| Capability | Traditional Architecture | Oracle Exadata |
|---|---|---|
| Failover Model | Active-Passive; minutes to hours of downtime | Active-Active RAC; sub-second session redirect |
| Storage Redundancy | Hardware RAID; full-drive rebuild bottleneck | ASM file-level mirroring; intelligent partial rebalance |
| Disk Failure Impact | Up to 80% IOPS consumed by RAID rebuild | Distributed rebalance across all remaining disks |
| Cell/Node Failure | Manual intervention; potential application outage | Automatic I/O reroute; Smart Scan redistribution |
| Split-Brain Protection | Depends on third-party clusterware quality | Oracle Grid Infrastructure with ASM voting disks |
| Patching Strategy | Full maintenance windows; planned downtime | Rolling patches via patchmgr; zero application downtime |
| Flash Write Protection | Single-array cache; data loss risk on power failure | Write-Back Flash Cache mirrored across cells |
| Site-Level DR | Separate DR project; often async with data loss risk | Native Data Guard integration; sync/async modes |
| Performance During Failure | Severe degradation; cache saturation on takeover | Linear capacity reduction (e.g., 8.3% per lost cell) |
| Client Failover | TCP timeout waits (minutes) | FAN + Transaction Guard + Application Continuity |
12 · Frequently Asked Questions
1. What is the difference between Normal Redundancy and High Redundancy in Exadata?
Normal Redundancy utilizes two-way mirroring and requires a minimum of three storage cells, allowing the system to survive the loss of one cell or disk. High Redundancy utilizes three-way mirroring, requires a minimum of five storage cells, and can survive the simultaneous loss of two storage cells or disks.
2. Does Oracle Exadata Smart Flash Cache lose data if a storage cell loses power?
No. If you are using Write-Back Flash Cache mode, Exadata automatically mirrors dirty cache blocks across separate storage cells. If one cell loses power, the unwritten data is safely available on a surviving cell's flash cache.
3. How does Application Continuity prevent users from seeing database errors?
Application Continuity masks database outages by hiding the error from the client application. It captures the session state and database commands at the driver level, and if a node fails, it transparently reconnects to a surviving node and replays the incomplete transactions without requiring user intervention.
4. Can I patch an Exadata Storage Cell while the database is running heavy batch jobs?
Yes. Exadata supports rolling storage patching. However, it is a best practice to run patches during lower-traffic periods to ensure that the remaining cells can easily absorb the I/O load without impacting performance-sensitive batch windows.
5. What role does the RoCE network play in Exadata High Availability?
The Remote Direct Memory Access (RDMA) over Converged Ethernet (RoCE) network provides an internal interconnect between compute and storage layers. Its ultra-low latency allows for fast cluster heartbeats and rapid block transfers via Cache Fusion, minimizing the time required to detect and fence failed nodes.
6. Is a separate backup appliance required if Exadata has built-in storage mirroring?
Yes. Storage mirroring protects against physical component failure, not data corruption, accidental deletions, or site-level disasters. You should complement Exadata with a dedicated backup target, such as an Oracle Zero Downtime Recovery Appliance (ZDLRA) or an RMAN-compliant backup solution.
7. What is a "Split-Brain" scenario, and how does Exadata prevent it?
A split-brain scenario occurs when cluster nodes lose communication with each other and each attempts to take control of the shared storage, which can lead to data corruption. Oracle Grid Infrastructure prevents this by using voting disks stored within ASM disk groups to safely isolate and fence off unhealthy nodes from the storage layer.
8. Does Active Data Guard replicate data asynchronously or synchronously?
Active Data Guard supports both configurations. Maximum Availability and Maximum Protection modes utilize synchronous replication, guaranteeing zero data loss over distance. Maximum Performance mode utilizes asynchronous replication, which avoids adding network latency to the primary database transactions but carries a slight risk of minimal data loss during an abrupt site failure.
13 · The Short Version — 8 Reasons Oracle Exadata Delivers High Availability
- Architecture-First DesignHigh availability starts with native software-hardware co-engineering, not just stacking redundant hardware components on top of each other.
- Automated ASM MirroringOracle ASM automatically mirrors data, detects localized disk faults, and rebalances storage groups without requiring manual intervention from a DBA.
- Active-Active RAC ProcessingOracle RAC enables multiple database instances to actively serve user requests simultaneously, ensuring seamless continuity even if a compute node drops offline.
- Transparent Storage Cell FailoverComplete storage cell outages are handled automatically by ASM and redundant interconnects, ensuring zero interruption to the database layer.
- Performance PreservationSmart Scan, Smart Flash Cache, and distributed cell processing work together to maintain enterprise-grade throughput even when components fail or are recovering.
- Zero-Downtime Rolling MaintenanceSoftware patches, OS updates, and storage cell firmware upgrades can be applied one node at a time without taking the database application offline.
- Geographic Disaster RecoveryOracle Data Guard extends protection beyond local hardware failures, providing remote data replication and failover capabilities for entire site outages.
- Unified Ecosystem ResilienceBy combining automated redundancy, smart clusterware orchestration, and deeply integrated software, Exadata delivers high availability alongside consistent, predictable performance.
Traditional infrastructures often force organizations to choose between maximum performance and maximum availability. Oracle Exadata was engineered so that resilience is part of the architecture itself — not a compromise added later.
Resilience Built In, Not Bolted On
Oracle Exadata doesn't ask you to choose between uptime and speed. ASM, RAC, Smart Flash Cache, and rolling maintenance work as one coordinated system — so failures become background events instead of production incidents.
At ExaGuru, our Exadata Expert course covers ExaCC, ExaCS, ASM redundancy design, RAC failover tuning, and production HA patterns — because understanding the architecture is the first step to trusting it under pressure.